Spark Yarn Cluster
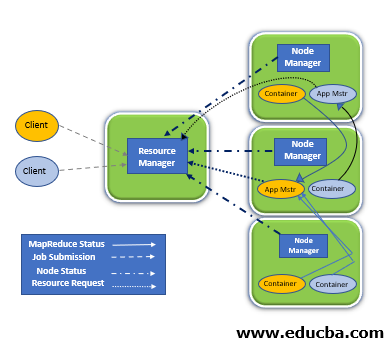
- Spark Submit Cluster(Yarn)->(Hadoop+Spark)
- Spark Lens Integration is a profiling tool to check the memory allocation(executor memory, etc.)
- Spark has Hash Partition which is the same algorithm used by MapReduce also.
- Map(Parallelism which acts as input), Reduce(Aggregation which acts as output)
- No of blocks=No of tasks when it is HDFS.
- No of O/P tasks=No of I/P tasks
- Spark uses the algorithm called hash partition to decide which particular output partition should be set to particular output task.
- Hash Partition(output partition)=(Hash of the key)%(No of output task count)
Few Commands
- data.getNumPartitions (It is used to get no of partitions)
- reducedata.repartition(3).saveAsTextFile("out.txt");
- Removing Null Values
- df.dropna(how="any").show() #removes row if any one column is null
- df.dropna(how="all").show() #removes row if all columns are null
- df.dropna(how="any",subset=["salary"]).show() #removes column if any null value is found
- df.dropna(how="any",thresh=2).show() #more than or equal to 2 values then it will display
Repartition or Coalesce
- Repartition is to increase the no of partitions(parent+new)
- When it is performed total data will be reshuffled and it needs to be tuned again.
- It can be used to increase and decrease partition but it depends on data.
- Coalesce is to reduce the no of partitions(new)
- The shuffle doesn't happens here so the performance increases.
- But parallelism is lost and it's not fast in all cases.
GroupbyKey vs ReducebyKey

- ReduceByKey is prefered for calculations
- ReduceByKey uses (MR-Combiner) for it's tasks.
- Uses reducer logic
- It's a mini reducer
Other important points
- Spark Dedup is a process of removing duplicates from a table.
- dropDuplicates (column_name).show;
- The duplicates is due to the type of data provided by source.
- The duplicates will be created when the scheduler(oozie) is failed and it restarted.
- PySpark UDF is slow in python it is suggested to use other languages to overcome this challenge.
- Moving Average Calculation=((-1)+(1)+(0))/3
- Spark MLib is used to calculate FP Growth(Frequent Pattern)
- confidence=pq where p=4(constant)
- CrossTab in PySpark is used to represent frequency between two or more than 2 variables(frequency distribution).
- df.crosstab("name","age").show()
- size of cluster=size of system(sum of nodes size)


Comments
Post a Comment