NOSQL Database and Pipeline tool
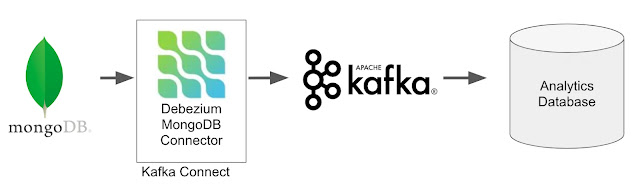
Kafka is a data pipeline tool. Zookeeper is needed before installing Kafka as its a cluster coordinator. Kafka stores all metadata information in zookeeper. NOSQL CAP is not possible at a time in NOSQL databases. Products like Facebook, Instagram achieves CAP by using multiple databases. CA is not possible at a time because of partition. In RDBMS no replication is present so CA is achieved. Ex: Hbase, MongoDB, Cassandra Datastores Keyvalue Datastore(Reddis) ColumnOriented Datastore(Hbase, Cassandra) DocumentOriented Datastore(MongoDB) Graph Datastore(Neo4j) Hbase is used for internal operations Lookup(veryfast) upset(insert+update)



